**CS59 Project - Visualising Trees DSL**
Andreea Chiriac, Atanas Iliev, Ethan Liu
This document serves as a project proposal and later, documentation, for the CS59 term-long project by Andreea Chiriac, Atanas Iliev, and Ethan Liu.
For the current milestone 2, it details the implementaion of our DSL grammar into a functioning parser.
Domain
=============
Our chosen domain is the visualization of different tree diagrams in various settings. Initially prompted by the difficulty of graph-theorists to visualize their diagrams
in LaTeX, we soon realized that a certain sort of graphs, trees, are common outside of Mathematics and CS as well, and many experts in fields related to tree diagrams
may not possess the necessary software-development skills to easily describe their trees in a computer environment. Some areas where our language may find applications include
family/hereditary trees, taxonomy, probability, and consulting (an example of the last will be a tree detailing a large company's management structure).
Problem Definition
=================
To help the aforementioned fields, it will be useful to define the problem we are facing and then tackle it in several steps. In essence, we want to make it possible for
non-experts (in CS) to be able to easily and quickly describe a tree diagram that our language can then turn into a graphic they recognize. To do that we need to:
1) Find a way to easily describe trees in a textual format.
2) Write a grammar for the syntax of the language.
3) Interpret the textual input according to a set of semantics.
4) Visualize the interpreted input.
All these are quite broad and might undergo severe modifications and detailed review before they are completed.
Sample Solutions
================
In this section, we will provide two working and several error-containing examples of what the language we hope to develop might take as input and produce as output.
The input we provide will be written directly in this HTML document whereas the output for the working examples will be hand-drawn in Goodnotes or Nebo and uploaded as pictures.
First, let us start with an example of a family tree.
Example 1: British Royal Family
--------------------------------
~~~~ Python linenumbers
Charles
Diana 1:d
William 1+2
Catherine 3:m
George 3+4
Charlotte 3+4
Louis 3+4
Harry 1+2
Meghan 8:m
Archie 8+9
Lilibet 8+9
Camilla 1:m
~~~~

Next, consider an example related to consulting.
Example 2: Apple Corporate Structure
--------------------------------
~~~~ Python linenumbers
Arthur Levinson
Tim Cook 1+1
Jeff Williams 2+2
Marketing 3+3
Engineering 3+3
HR 3+3
~~~~

The last three examples detail several different syntax and semantics errors. Discussion on all examples is found in the next section.
Example 3: Indentation and Invalid Character Errors
--------------------------------
~~~~ Python linenumbers
a
b
c z:m
d
e 3+4
~~~~
Syntax error on line 2: Too many indentations (2), maximum allowed (1).
Syntax error on line 3: 'z' in 'z:m' must be a number.
Example 4: Level Misalignment Error
--------------------------------
~~~~ Python linenumbers
a
b
c 1+2
d 2:m
e 3+4
~~~~
Semantics error on line 4: Attempts to marry at a different level.
Example 5: Potentially Nonexistent Line Error
--------------------------------
~~~~ Python linenumbers
a
b
c 1+2 4:m
d
e 3+4
~~~~
Semantics error on line 3: 4 in '4:m' is larger than current line number (3).
Functionality
======================
Finally, in this section, we discuss some of the fundamental functionality principles behind our language as we intend them as of now drawing on the examples
provided in the previous section. As one can see, different levels are defined by indentation. As such, any line has an allowed number of indentations in its beginning
to ensure that the structure of the graph indeed resembles a tree. This is exactly the cause of one of the syntax errors in Example 3. On line 2, there the maximum number
of indentations is 1 because the first line is not indented at all. We like the indentation system because it is easy and intuitive to work with. One drawback is that certain
lines may get too long provided there are enough levels in the tree. While the simplest solution is to replace the tab with a single whitespace character, this would make
the input significantly more confusing to write because single character whitespaces can be used at other locations in a line as well (like between names).
After indentation each line is followed by a name. As seen in Example 2 the name may be more than one word. We are also considering allowing the name to contain characters
different than letters (a period for middle initials, numbers for probability trees, etc.). Given this it might become necessary to enclose the name by certai characters
like () or "" to help the parser understand which part of the line exactly constitute the name.
We then continue with an optional 'N+N' part where N is a number. These two numbers indicate the parents of a given line/item in the tree. Usages of this can be seen in both
Examples 1 and 2. In Example 2, we can see that a line can have just 1 parent. To do that we make sure the 2 Ns are identical. We are considering expanding this by allowing
this part of the line to have more than one '+N' after the first 'N' so that a child line can have more than 2 parents. If we proceed with this, we can simplify Example 2,
by, for example, having just '____Tim Cook 1' for line 2.
Last, before the newline symbol each line ends with 0 or more 'N:C' where N is again a number and C is a (special) character. In our examples, we used 'm' and 'd' for
married and divorced respectively, but we might change those to more general stuff like '-', '=', '.' to avoid the family context given that essentially they translate
into different styles of lines. The number before the colon indicates the line with which the current line must be connected by a segment of the style required by the character
after the colon. Example 1 illustrates two different styles (solid for marriage and dashed for divorce). Several syntax and semantics errors can arise from this. A simple one
might be a syntax error as the one in Example 3 which has 'z:m' instead of N':m'. However, semantics error are more interesting. First, we must make sure we are not trying
to establish relationships on different levels than the current one as in Example 4. While this is not impossible (poor Oedipus) we will only allow it if we have the time
to make our interpreter and visualizer smart enough. Second, we must avoid the mistake from Example 5 where we try to establish a relationship
with a line below the current one. This is dangerous because the line we are referencing may not exist. There is an easy set-theoretic proof (in addition to it being intuitively
the case) that this restriction does not limit expressiveness.
This is all we have for now in terms of functionality and it will most likely change in at least some aspects as we actually go to develop the grammar and the rest
of the project.
Grammar
========================
In this section, we provide a grammar for the language written in pseudocode Java/ANTLR. In essence, the defining challenge of our language is the management of different whitespaces.
Whereas many simple languages can get away with ignoring whitespaces entirely, ours is reliant on indentation and hence this is not really an option.
First, however, let us go over the basic structure of the grammar. We start with a **start** non-terminal that is a one or more **line** non-terminals followed by an **EOF** terminal.
Each line is then a series of indentations followed by a **name** non-terminal an optional **parents** non-terminal and zero or more **relations** non-terminals. A **name** is one or more
**word** non-terminals. A **word** is one or more **LETTER** terminals. The **parents** non-terminal is just a **number** followed by a '+' character followed by another **number**. A **number**
is a **NON-ZERO-DIGIT** terminal followed by a zero or more **DIGIT** terminals. Similarly, a **relations** is a **number** followed by a ':' character followed by a **SPECIAL** terminal. The last
is just one of several characters such as 'm' or 'd' from our examples above.
Now, we move to the discussion of various whitespaces. We distinguish between three main types of whitespace. A *space* character ( ), an *indent* (____), by default defined as four *space*
characters, and a *newline* (\n) (we are aware of different stuff such as \r for now we don't discuss that). While we believe that a \t is usually defined as eight *space* characters, for now we
treat \t as a substitute for an *indent*.
Note that we assume that ANTLR is able to easily distinguish between an *indent* and a *space*. If that is not the case, our grammar we will become a bit more complex but it will be more of a
technicality than a concept-related problem. One possible approach would be to define our own **INDENT** and **SPACE** terminals, add an optional number of the latter where we are now simply
directing the parser to ignore *space* characters, and then proceed to do nothing with these terminals.
At last, we are able to address the difficult part, specifically, what we do about the indentation at the beginning of each line. At first, one might think that something like this is enough:
~~~~
line: (INDENT)* name (parents)? (relations)* ;
~~~~
Unfortunately, Example 3 in Section 3 illustrates why this won't work. We want to ensure that each line is indented at most once more than the line directly preceding it.
Attempt 1: Recursive Definition
--------------------------------
Our first attempt
to solve this was unfortunately unsuccessful. Nonetheless, it is worth examining.
~~~~
start: (line)+ EOF ;
line: name (parents)? (relations)* '\n' (INDENT line)* ;
~~~~
(Fun fact: This implementation does not ignore new lines and furthermore requires that the input file contains an empty line before the **EOF** terminal.)
By recursively implementing the **line** non-terminal we were hoping to force our grammar to permit at most once indentation more than the one on the previous line. In fact, it is somewhat
successful in that it successfully eliminates all invalid inputs where the problem has to do with indentation. However, it also fails to parse the majority of the valid ones. To see one we
can get back to Example 1 (the one about the British Royal Family). Consider the first three lines of that input file
~~~~ Python linenumbers
Charles
Diana 1:d
William 1+2
~~~~
If we try to apply our grammar we begin at the **start** non-terminal and immediately after enter a **line** which in our case we recognize as a **name** followed by a new line and by
an (**INDENT** **line**). That **line** is then a **name** (Diana) followed by a **relations** and a new line. So far so good. Now, we must decide how to parse the third line. We have two
options. We can exit the current **line** and go back to **start** or continue by searching for an **INDENT** and a **line**. If we choose the former we exit the Diana **line** and enter a
new **line** from the **start** non-terminal. As the first thing we see is an **INDENT** we return an error. If, instead, we choose the latter approach, we encounter an **INDENT** but then
another **INDENT** instead of a **name** (the first part of a **line**). Hence, we must return an error again. We were mistaken because we are used to text editors and IDEs which automatically
keep the current indentation when the user applies a new line (for example by clicking return) when writing stuff like Python code. Since the parser has no way of doing that, we had to scrap
this first approach.
Attempt 2: Single Last Indentation
----------------------------------
Our second attempt was even less successful. We returned to an explicit (non-recursive) grammar and added a special character before the last indentation at the beginning of each line from the input
file.
~~~~
line: (IGNORE)* '|' (INDENT)? name (parents)? (relations)* ;
IGNORE: \t ;
INDENT: \t ;
WS: [IGNORE \n]+ -> skip ;
~~~~
The necessity of having the '|' is caused by the inability to otherwise distinguish between an **IGNORE** and an **INDENT**. The idea is that checking whether an **INDENT** is present on a given
line is the same as checking whether we need to go down a level. Hence, we ignore other indentation and newlines in the parser. This approach is successful in distinguishing when we should go down
a level (exactly when an **INDENT** is present) and does not discriminate against the otherwise valid inputs unlike Attempt 1. However, it introduces much more severe issues. First, it has no way
of distinguishing whether we should stay on the same level or go back one level up whenever an **INDENT** is not found on a given **line**. Second, it doesn't actually solve the original problem.
In a version of Example 3 from before, it would only catch the syntax error if the file is written as shown on the LHS, whereas the one on the RHS will still be valid which makes the language
extremely counterintuitive...
~~~~ Python linenumbers
a
| b
| c
~~~~
[Invalid]
~~~~ Python linenumbers
a
| b
| c
~~~~
[Valid]
Even more misleading, the input file on the RHS will be interpreted as if it was written in the following way (in the orignal syntax):
~~~~ Python linenumbers
a
b
c
~~~~
Hence, we had to scrap that approach as well and at last settled for a version of what other indented languages such as Python are doing.
Attempt 3: Indentation Tracking Variables
----------------------------------
Once again the **start** non-terminal will require one or more **line** non-terminals. We will ignore newline characters. On each line we will call a function via an embedded action that will compare
the number of **INDENT** tokens on the current line to that on the previous line. In case the former is larger than the latter by two or more a syntax error will be returned and the parser will
terminate. The function itself is quite simple. We need two variables, *former* and *current*, both of them being integers set to 0 in the beginning. The moment we enter a **line** non-terminal, we set
*former = current* and then *current = 0*. Then every time we produce an **INDENT**, we increment *current* by 1. The moment we get something other than indentation, we check *current - former > 1*
and in case of a **true** spit out an error. If not we do nothing and exit the function. The variables are global since we need to know the value of *former* from the previous *current* and this is
not a problem since we reset *current* in each **line** non-terminal. We can call this function *correctIndentation()*.
Last, we mention that we can't simply ignore **SPACE** characters. This is because (assuming we set \t to 4 space characters), we don't want a line beginning with say 9 spaces to count as valid.
To ensure that we allow an optional number of **SPACE** tokens wherever necessary (we don't have to be too strict and check that there is just one of them between two relations for example) and do
nothing with them in the translator.
Thus, our grammar becomes:
~~~~ ANTLR linenumbers
start: line (NEWLINE line)* EOF ;
line: (INDENT)* name (SPACE)* (parents)? (SPACE)* (relations)* {correctIndentation()} ;
name: word (SPACE word)* ;
parents: number '+' number ;
relations: number ':' SPECIAL ;
word: (LETTER)+ ;
number: NONZERO (DIGIT)* ;
LETTER: [a-zA-z] ;
NONZERO: [1-9] ;
DIGIT: [0-9] ;
SPECIAL: 'm' | 'd' ;
SPACE: ' ' ;
INDENT: '\t' ;
NEWLINE: '\n' ;
~~~~
Examples
----------------------------------
The following image is a representation of an example and how the Grammar applies to it. The example is a modified version of the one in section 3.2, where the tweak resides in adding "4:d" to the last line, to indicate that "Marketing" and "HR" are "divorced", i.e. at some point in time they were part of the same branch that eventually split in two.
Hence, the user input would be:
~~~~ Python linenumbers
Arthur Levinson
Tim Cook 1+1
Jeff Williams 2+2
Marketing 3+3
Engineering 3+3
HR 3+3 4:d
~~~~

And the respective Grammar tree would be:

On the other hand, the example in section 3.3 would return an indentation error: {correctIndentation()} - False (2 indentations instead of 1).
Parser
========================
In this section, we go over the implementation of the grammar in a working parser using ANTLR and Java. In short, we had to write three files.
An ANTLR grammar file called Expr which also includes an embedded action for the indentation rules, a parser Java class called Test for testing
(we couldn't just use the Test Rule functionality of the ANTLR plugin because it would not be able to catch whether the indentation is correct),
and a custom listener that extends the base one generated from the grammar file to throw exceptions when the parser catches something incorrect.
We discuss each of these one by one starting with our grammar file.
~~~~ ANTLR linenumbers
grammar Expr;
@parser::header {
import java.util.Stack;
}
@parser::members {
Stack indentationLevels = new Stack<>();
int lastIndentationLevel = 0;
private void correctIndentation(int currentIndent) {
if (!indentationLevels.isEmpty()) {
int lastIndent = indentationLevels.peek();
if (currentIndent > lastIndent + 1) {
throw new RuntimeException("Invalid indentation level: " + currentIndent + ". Expected: " + lastIndent + " or " + (lastIndent + 1));
}
}
indentationLevels.push(currentIndent);
}
}
start: firstLine (NEWLINE line)* EOF ;
firstLine
: name (SPACE)* (parents)? (SPACE)* (relations)?
{ correctIndentation(0); } // Ensure no indentation on the first line
;
line
: indent+=INDENT* name (SPACE)* (parents)? (SPACE)* (relations)?
{ correctIndentation($indent.size()); }
;
name: WORD (SPACE WORD)* ;
parents: number '+' number ;
relations: number ':' special ;
number: NONZERO DIGIT* ;
special: SPECIAL ;
SPECIAL: 'm' | 'd' ;
WORD: [a-zA-Z]+ ;
NONZERO: [1-9] ;
DIGIT: [0-9] ;
SPACE: ' ' ;
INDENT: ' ' ; // 4 spaces
NEWLINE: '\n' ;
~~~~
Before addressing the correctIndentation() function, let us first cover some technical details about the implementation of the grammar rules.
There are four main differences with the pseudocode provided in the previous section that we need to consider. First, one can see that the
**INDENT** terminal has been defined as 4 space characters rather than a '\t'. This is something we changed after using the plugin Test Rule.
Turns out ANTLR interprets the pressing of the tab button as 4 spaces and not a \t.
Second, the reader may note a curious and at first glance useless peculiarity. The **special** none-terminal is just the **SPECIAL** terminal.
This was the only way we figured of getting around an issue we kept encountering. The characters 'm' and 'd' can be both a **WORD** terminal
and a **SPECIAL** terminal. Depending on which one we defined first in the grammar, the Test Rule would only recognise them as such and hence
always return an error in a line like "Camilla 1:m" (one where 'm' is contained in both a **name** and a **relations**). Given that a **WORD** is
only accessible through a **name** it turned out that making a **SPECIAL** only be accessed through a **special** (non-terminal) solved this issue.
Third, note the difference between a **firstLine** and a **line**. This is an inefficiency that does not impede functionality but is nonetheless
far from optimal. The reason behind its presence is that after hours of struggling to implement the correctIndentation correctly, we finally
succeeded with the exception that it will allow any indentation on the first line where our original idea of the grammar rules demanded that
the first line is never indented. We settled on making a separate rule for the first line which does not include the
optional indentation and called it a day.
Last, the thing that took the longest to solve and is the hardest to spot. Can you detect this small irregularity? In the **line** non-terminal
the reader may wonder why we have indent+=INDENT* instead of indent=INDENT*. This was awful. The explanation lies in the line immediately after that one.
As you can see correctIndentation takes indent.size() as a parameter. Nothing weird about that, right? After all, it is just supposed to compare a
number to another number. Well, size() is a method only lists have. And while it might be clear why an INDENT itself is not a list, we believed
for a long time that INDENT* will make indent a list. But not according to the generated parser who kept on insisting that indent was a Token and not
a List of Tokens.
After several different attempts to fix this, the one thing that worked and we discovered accidentally was to add the zero or more INDENTs to indent
instead of simply assign them to it. This ensured that indent is a List of Tokens and that we can use size() on it.
With that short introduction on the technical differences with the pseudo code, let us consider the correctIndentation structure. It is, in essence,
a very simplified version of what other indented languages like Python do. We use a structure, in our case a stack seemed the most reasonable one.
We first initialize the last indentation to be 0. Then in the function we check if the stack is empty and if it is not we compare the top element
with the last indentation variable. If the difference is more than one we throw an exception. Last, regardless of whether the stack is empty, we
add the current indentation level to it so that it is the top element the next we need to look at it.
We can now move to discussing the parser file and the custom listener.
~~~~ Java linenumbers
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.tree.*;
import java.nio.file.*;
import java.io.IOException;
public class Test {
public static void main(String[] args) {
String filePath = "inputs/test.txt";
try {
String input = new String(Files.readAllBytes(Paths.get(filePath)));
CharStream charStream = CharStreams.fromString(input);
ExprLexer lexer = new ExprLexer(charStream);
CommonTokenStream tokens = new CommonTokenStream(lexer);
ExprParser parser = new ExprParser(tokens);
parser.removeErrorListeners();
parser.addErrorListener(ThrowingErrorListener.INSTANCE);
try {
ParseTree tree = parser.start();
System.out.println("Parse succeeded: " + tree.toStringTree(parser));
} catch (RuntimeException e) {
System.err.println("Parse failed: " + e.getMessage());
}
} catch (IOException e) {
System.err.println("Error reading file: " + e.getMessage());
e.printStackTrace();
}
}
}
~~~~
This is just a standard parser that takes the input from a file instead of directly from a string. We give the file path and then read everything from there and collect in a string.
We then make a stream of characters and feed it to the lexer. we use the lexer to generate a stream of tokens and then in turn feed those to the parser. So far we only use the
stuff generated by ANTLR from the grammar we have written. We then replace the normal error listener with our own (provided below). We try the start rule from the parser and want
to store it in a tree. If we get this tree we print it and the parsing is deemed a success. If not we throw an exception. We also throw an exception if there's something wrong with
the file path or the reading of the file.
~~~~ Java linenumbers
import org.antlr.v4.runtime.*;
public class ThrowingErrorListener extends BaseErrorListener {
public static final ThrowingErrorListener INSTANCE = new ThrowingErrorListener();
@Override
public void syntaxError(Recognizer recognizer,
Object offendingSymbol,
int line, int charPositionInLine,
String msg,
RecognitionException e) {
throw new RuntimeException("Syntax error at line " + line + ", char " + charPositionInLine + ": " + msg);
}
}
~~~~
Here is the custom listener. The only thing we changed from the base one is the handling of syntax errors so that we understand which line (not the
non-terminal but the number) is causing trouble and at which character.
Valid and Invalid Examples
--------------------------------
Last, here are some examples and the output from the parser. To test other examples please replace the text in the file test.txt in the inputs resources folder.
Please keep in mind that our parser can only test one example at a time in its current form.
Example 1: Correct
~~~~ Python linenumbers
Charles
Diana 1:d
William 1+2
Catherine 3:m
George 3+4
Charlotte 3+4
Louis 3+4
Harry 1+2
Meghan 8:m
Archie 8+9
Lilibet 8+9
Camilla 1:m
~~~~
(We provide a screenshot for the first correct and incorrect examples. Beyond this, we just copy pasted the console output for the other 4 invalid inputs only:)
Result from the parser:
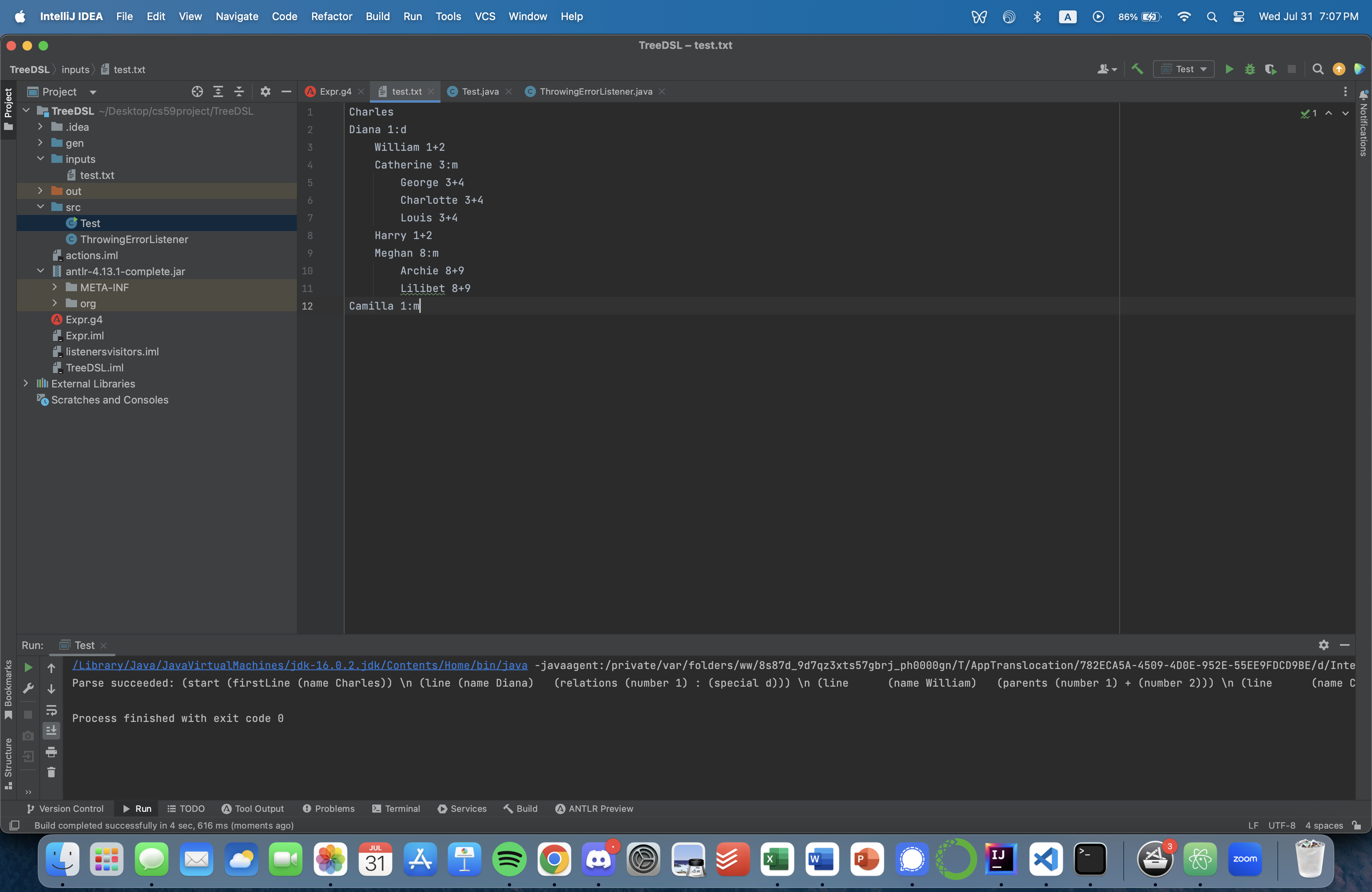
~~~~
/Library/Java/JavaVirtualMachines/jdk-16.0.2.jdk/Contents/Home/bin/java -javaagent:/private/var/folders/ww/8s87d_9d7qz3xts57gbrj_ph0000gn/T/AppTranslocation/782ECA5A-4509-4D0E-952E-55EE9FDCD9BE/d/IntelliJ IDEA CE.app/Contents/lib/idea_rt.jar=64591:/private/var/folders/ww/8s87d_9d7qz3xts57gbrj_ph0000gn/T/AppTranslocation/782ECA5A-4509-4D0E-952E-55EE9FDCD9BE/d/IntelliJ IDEA CE.app/Contents/bin -Dfile.encoding=UTF-8 -classpath /Users/atanasiliev/Downloads/libs/opencv.jar:/Users/atanasiliev/Downloads/libs/opencv-macosx-x86_64.jar:/Users/atanasiliev/Downloads/libs/javacv.jar:/Users/atanasiliev/Downloads/libs/openblas-macosx-x86_64.jar:/Users/atanasiliev/Downloads/libs/json-simple-1.1.1.jar:/Users/atanasiliev/Downloads/libs/net-datastructures-4-0.jar:/Users/atanasiliev/Desktop/cs59project/TreeDSL/out/production/TreeDSL:/Users/atanasiliev/Desktop/cs59project/TreeDSL/antlr-4.13.1-complete.jar Test
Parse succeeded: (start (firstLine (name Charles)) \n (line (name Diana) (relations (number 1) : (special d))) \n (line (name William) (parents (number 1) + (number 2))) \n (line (name Catherine) (relations (number 3) : (special m))) \n (line (name George) (parents (number 3) + (number 4))) \n (line (name Charlotte) (parents (number 3) + (number 4))) \n (line (name Louis) (parents (number 3) + (number 4))) \n (line (name Harry) (parents (number 1) + (number 2))) \n (line (name Meghan) (relations (number 8) : (special m))) \n (line (name Archie) (parents (number 8) + (number 9))) \n (line (name Lilibet) (parents (number 8) + (number 9))) \n (line (name Camilla) (relations (number 1) : (special m))) )
Process finished with exit code 0
~~~~
Example 2: Too Many Indentations
~~~~ Python linenumbers
Charles
Diana 1:d
William 1+2
Catherine 3:m
George 3+4
Charlotte 3+4
Louis 3+4
Harry 1+2
Meghan 8:m
Archie 8+9
Lilibet 8+9
Camilla 1:m
~~~~
Result from the parser:
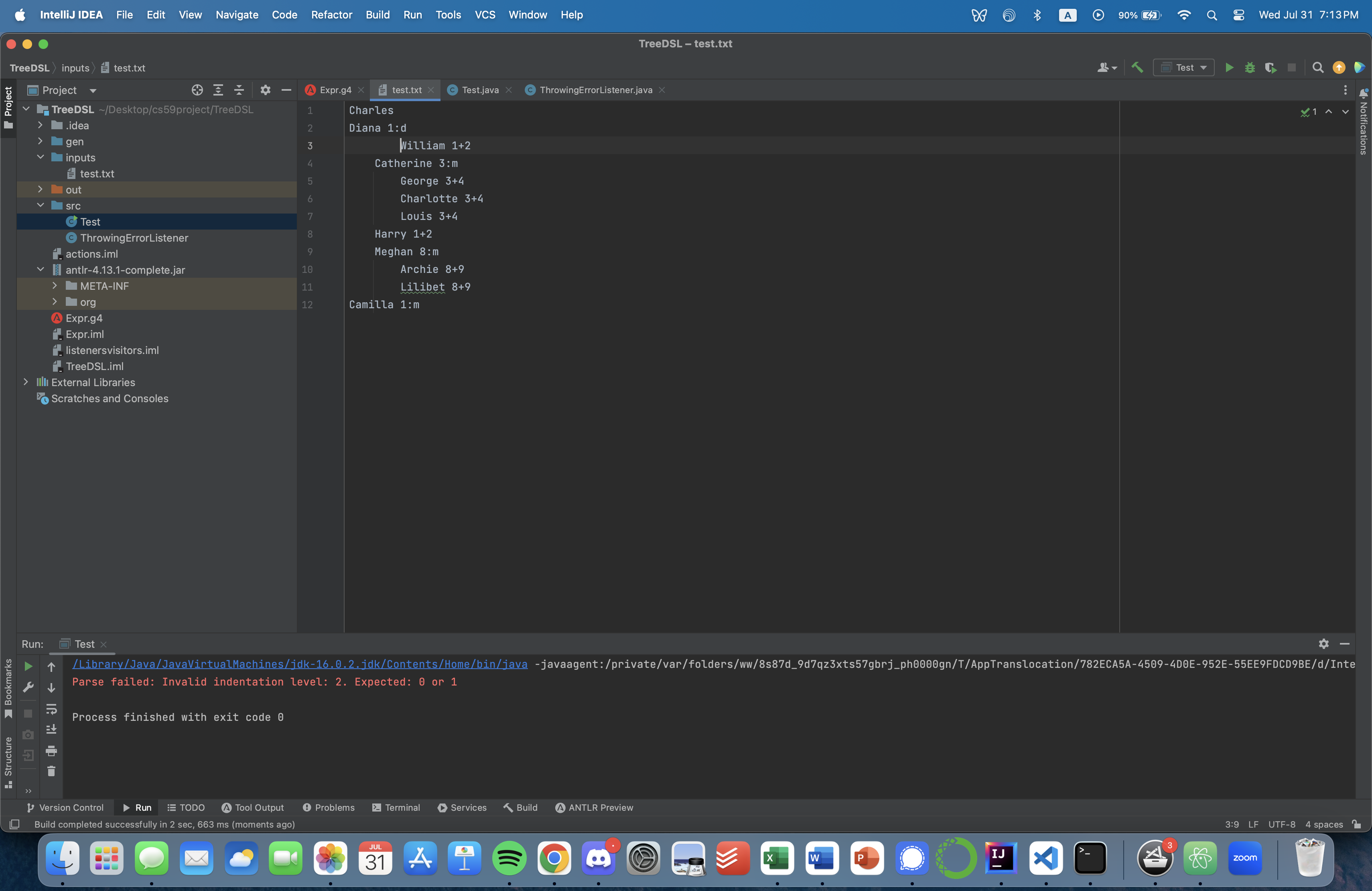
~~~~
/Library/Java/JavaVirtualMachines/jdk-16.0.2.jdk/Contents/Home/bin/java -javaagent:/private/var/folders/ww/8s87d_9d7qz3xts57gbrj_ph0000gn/T/AppTranslocation/782ECA5A-4509-4D0E-952E-55EE9FDCD9BE/d/IntelliJ IDEA CE.app/Contents/lib/idea_rt.jar=64672:/private/var/folders/ww/8s87d_9d7qz3xts57gbrj_ph0000gn/T/AppTranslocation/782ECA5A-4509-4D0E-952E-55EE9FDCD9BE/d/IntelliJ IDEA CE.app/Contents/bin -Dfile.encoding=UTF-8 -classpath /Users/atanasiliev/Downloads/libs/opencv.jar:/Users/atanasiliev/Downloads/libs/opencv-macosx-x86_64.jar:/Users/atanasiliev/Downloads/libs/javacv.jar:/Users/atanasiliev/Downloads/libs/openblas-macosx-x86_64.jar:/Users/atanasiliev/Downloads/libs/json-simple-1.1.1.jar:/Users/atanasiliev/Downloads/libs/net-datastructures-4-0.jar:/Users/atanasiliev/Desktop/cs59project/TreeDSL/out/production/TreeDSL:/Users/atanasiliev/Desktop/cs59project/TreeDSL/antlr-4.13.1-complete.jar Test
Parse failed: Invalid indentation level: 2. Expected: 0 or 1
Process finished with exit code 0
~~~~
The 10 tests we include (5 valid and 5 invalid inputs) are labeled as test#I or test#V, where # denotes the number of the test and the end letter is meant to inform whether that test should be successfully parsed or not (V for valid and I for invalid). Below we can see the outputs for the other 4 invalid input tests.
test2I
~~~~ Python linenumbers
Charles
Diana 1:d
William 1+2+3
Catherine 3:m
George 3+4
Charlotte 3+4
Louis 3+4
Harry 1+2
Meghan 8:m
Archie 8+9
Lilibet 8+9
Camilla 1:m
~~~~
~~~~
Parse failed: Syntax error at line 3, char 15: extraneous input '+' expecting {, '\n'}
Process finished with exit code 0
~~~~
test3I
~~~~ Python linenumbers
Charles
Diana 1:d
William 1+2
Catherine 3:M
George 3+4
Charlotte 3+4
Louis 3+4
Harry 1+2
Meghan 8:m
Archie 8+9
Lilibet 8+9
Camilla 1:m
~~~~
~~~~
Parse failed: Syntax error at line 4, char 16: mismatched input 'M' expecting {':', DIGIT}
Process finished with exit code 0
~~~~
test4I
~~~~ Python linenumbers
Charles
Diana 1:d
William 1+2
Catherine 3:m
George 3+4
Charlotte 3+4
Louis 3+4
Harry 1+2
Meghan 8:m
Archie 8+9
Lilibet 8+9
Camilla 1:m
~~~~
~~~~
Parse failed: Syntax error at line 1, char 0: mismatched input ' ' expecting WORD
Process finished with exit code 0
~~~~
test5I
~~~~ Python linenumbers
Charles
Diana 1:d
William 1+2 Windsor
Catherine 3:m
George 3+4
Charlotte 3+4
Louis 3+4
Harry 1+2
Meghan 8:m
Archie 8+9
Lilibet 8+9
Camilla 1:m
~~~~
~~~~
Parse failed: Syntax error at line 3, char 16: extraneous input 'Windsor' expecting {, '\n'}
Process finished with exit code 0
~~~~
You can find all the remaining valid tests we came up with in the inputs folder and test them if you want :).
ଘ(੭ˊᵕˋ)੭* ੈ✩‧˚
========================
Thank you for reading all that :D